Next: FAQ Up: Documentation about Sched Previous: Scripts Contents
You have to choose (with pwgen for example) a connexion password to sched_master. This password will not be used by human. Also it can have 50 character length.
This tutorial is an example which use only one node. Jobs will used plume hostname. The slave module will used plume2 hostname.
Sched database must be up and accessible. The structure must be ok and you have to know the connexion string (dns). (Cf 2.5)
sched_view cgi scripts have to be accessible on your mozilla throe apache. (Cf 2.6.2)
sched_job and sched_slave use a working directory (work_dir) to store some files. This directory have to be accessible to yours users (launching job or slave).
To manage connexion, each sched component use an internal storage area (db_dir).
mkdir -p /tmp/sched/wd mkdir -p /tmp/sched/master/db mkdir -p /tmp/sched/slave/db mkdir -p /tmp/sched/job/db
localhost:~/ cat /etc/sched/master.cfg [main] logfile=/tmp/master.log debug=5 [master] job_dir=/tmp/sched/job db_dir=/tmp/sched/master/db dsn=dbname=sched;user=sched;password=xxx group=sched user=nobody master_port=5544 view_passwd=motdepass view_ip=127.0.0.1
localhost:~/ cat /etc/sched/cgi.cfg [main] logfile=/tmp/cgi.log debug=0 [cgi] master_ip=localhost master_port=5544 master_passwd=motdepass master_retry=10 view_passwd=motdepass dsn=dbname=sched;user=sched;password=xxx xfer_port=8081
localhost:~/ cat /etc/sched/slave.cfg [main] logfile=/tmp/slave.log debug=5 [xfer] xfer_inet = 0.0.0.0 xfer_port = 5545 xfer_user = nobody xfer_group = nogroup [slave] master_ip=localhost master_port=5544 master_passwd=mdpplume2 master_retry=10 work_dir=/tmp/sched/wd db_dir=/tmp/sched/slave/db hostname=plume2
localhost:~/ cat /etc/sched/job.cfg [main] logfile=/tmp/job.log debug=5 [job] work_dir=/tmp/sched/wd job_dir=/tmp/sched/job master_ip=localhost master_port=5544 master_passwd=mdpplume master_ping=30 db_dir=/tmp/sched/job/db hostname=plume
The cgi http://localhost/cgi-bin/sched/sched_list_host.cgi permit to add tutorial hosts.
Using sched_builder permit to build a job. (see http://www.nongnu.org/sched/doc/tutorial1.swf)
On command line, utility sched_job_validate can validate your job.
localhost:~# sched_job_validate -j jobname.xml [24/10/2004 15:15:49] <5> Sched::init: I : Demarrage I : verification ok
Go on http://localhost/cgi-bin/sched/sched_commit_job.cgi and upload your job file.
On command line, utility sched_job_commit can validate your job and use it in production.
localhost:~# sched_job_commit -j jobname.xml \
-r 'version 1 - test before prod'
[24/10/2004 15:15:49] <5> Sched::init: I : Demarrage
I : verification ok
I : OK 19 is registred
If your job is not ok, it will not be commit in sched database.
When your job is committed in database, you can use it in network environment. Network mode permit to keep history of each execution and launch task on other network host. In this version, deploying a job is manual, you have to copy job file on targeted host in the job_dir. This host must be allowed to execute the job (host field in job properties)
When your job is installed on your target server, the sched_job -dry-run option permit to simulate job execution. Each command will be replaced just before execution by a nop command (sleep 1).
This option permit you to test servers, path, I/O files, users, groups etc...
localhost:~# sched_job -j job.xml --dry-run
The sched_job program is in charge of executing the job.
localhost:~# sched_job -j job.xml
On Unix system with cron
0 5 * * sched_job -j job.xml > /dev/null 2>&1
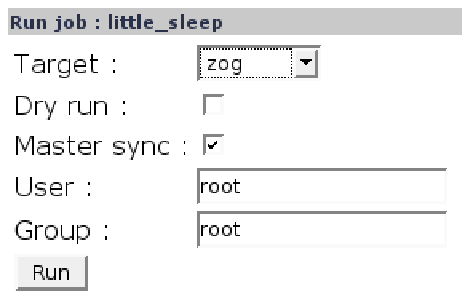
sched_view permit to launch job on connected slaves. (cf fig 10 and 11)
Job version depend on his md5 checksum. You cannot edit the job file after deploying. You must commit it again.
Eric 2005-12-17
![\includegraphics[width=13cm]{inc/sched_view_run.eps}](img10.png)